DockerのサブセットをRustで自作した (Docker + Rust = Rocker 🤟)
DockerのサブセットをRustで自作してみました。
詳細な実装の解説はこの記事では行っていないので、気になる方はソースコードをご参照ください🙏
概要

今のところ以下の機能が実装されています。
- コンテナの実行 (
docker run相当) - 実行中のコンテナ一覧の取得 (
docker ps相当) - pull済みのイメージ一覧の取得 (
docker images相当) - 実行中のコンテナ内で新しいコマンドを実行 (
docker exec相当) - イメージの削除 (
docker rmi相当)
自作しようと思ったきっかけ
Kubernetes 1.20 からDockerが非推奨になったときに、さほど利用者には影響がないにも関わらず自分はなんとなく慌ててしまい、Dockerを雰囲気で使ってることに気づいたのでDockerがどうやって動いてるのかを理解するためにDocker (のサブセット) を自作してみました。
Dockerを自作しているプロジェクトはすでにいくつか存在し、有名なものだと100行程度のシェルスクリプトで実装しているBockerやGoで実装されているGockerなどがあります。今回はBockerやGockerのコードを参考にしながら自作Dockerの実装を行いました。
大まかな実装の説明
コンテナを実行するにあたり使った技術は基本的にはDocker (runc) と同じで、プロセスの分離には namespace や chroot、リソースの制限には cgroup (v1 / v2) を使いました。詳細な実装はぜひRockerのソースコードを読んでいただけるとありがたいです。
ネットワーク構成についてもほとんどDockerのbridgeネットワーク (下図) と同じような構成になっています。ネットワークについては私があまり詳しくないということもあり、既存プロジェクトのコードを読んでもよく分からなかったのですが こちらの記事 はとても分かりやすくまとめられており助かりました。

学んだこと
- コンテナを実行するために使われている技術 (Linuxの機能) についての理解が深まった
- Rustで何か作るのは初めてだったが、だいぶRustの雰囲気に慣れてきた
xv6-riscv のメモリ管理方法
この記事は自作OS Advent Calendar 2020 - Adventarの14日目の記事です。
概要
YouTubeに公開されているMITのOSの講義を(勝手に)受けていて、xv6のメモリ管理について理解した(つもりになった)ので自分なりにまとめておく。具体的にはページング、メモリレイアウト、ユーザー空間のメモリ 割り当て/回収 の流れについてまとめる。
まとめるにあたって講義テキスト*1やThe RISC-V Reader*2を参考にした。
xv6とは
xv6とはMITのOSの講義で使われている教育用のOSで、UNIX V6をベースにしている。2018年まではx86_64向けしかなかったが、2019年にRISC-V向けが公開され講義でもこちらを使うように変わった。
x86_64バージョンのgithubレポジトリ(xv6-public)
RISC-Vバージョンのgithubレポジトリ(xv6-riscv)
ページング
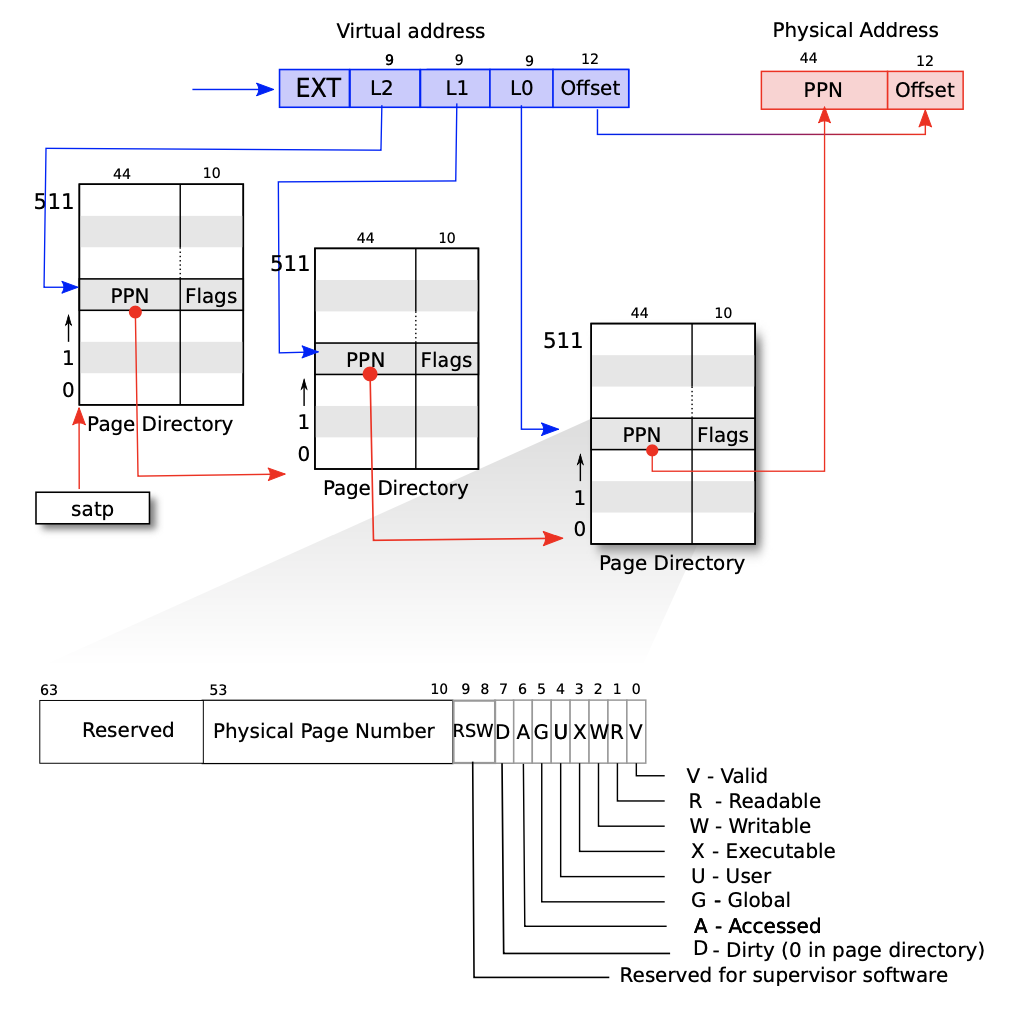
RISC-Vのページング機構は仮想アドレスのビット数 (X)に応じて、SvXという名前がついている。具体的には下表のような種類があり、xv6-riscvではSv39を採用している。

Sv39は39 bitの仮想アドレス空間 (512 GiB) を表現でき、3段構成のページテーブルで、ページサイズは4 KiBになっている。各ページテーブルは29 個のページテーブルエントリ (PTE)を保持しており、各PTEの大きさは8 byteなのでページテーブル自体の大きさは4 KiB ( 8 byte * 29 個) となる。PTEの内容は下図のようになっており、下位10 bitはPTEの権限やPTEが有効かどうかなどを表すフラグで、上位44 bitで物理アドレスを表す。

仮想アドレスから物理アドレスへの変換は下のような手順で行われる。
1. satpレジスタに保存されている1段目のページテーブルの物理アドレスを取得する。
2. 1.で取得した物理アドレスに、仮想アドレスの下位31~39ビットを足した物理アドレスに格納されているPTEを取得する。
3. 2.で取得したPTEが指す物理アドレスに、仮想アドレスの下位22~30ビットを足した物理アドレスに格納されているPTEを取得する。(2段目のページテーブルからPTEを取得)
4. 3.で取得したPTEが指す物理アドレスに、仮想アドレスの下位13~21ビットを足した物理アドレスに格納されているPTEを取得する。(3段目のページテーブルからPTEを取得)
5. 4.で取得したPTEが指す物理アドレスに、仮想アドレスの下位1~12ビットを足したアドレスが変換後の物理アドレスになる。
カーネル空間のメモリレイアウト
xv6-riscvはqemu上で動くことが想定されており、qemuの仮想マシンでは物理アドレスは下図右のようなレイアウトになっている。物理アドレスの0x8000_0000から0x8640_0000にRAM (物理メモリ)が配置され、0x8000_0000以下にはI/OデバイスがメモリマップドI/Oで配置されている。物理アドレスの0x0000_0000から0x8640_0000までは、仮想アドレスは物理アドレスと同じ値にマッピングされている (講義中ではダイレクトマッピングと呼んでいた)。
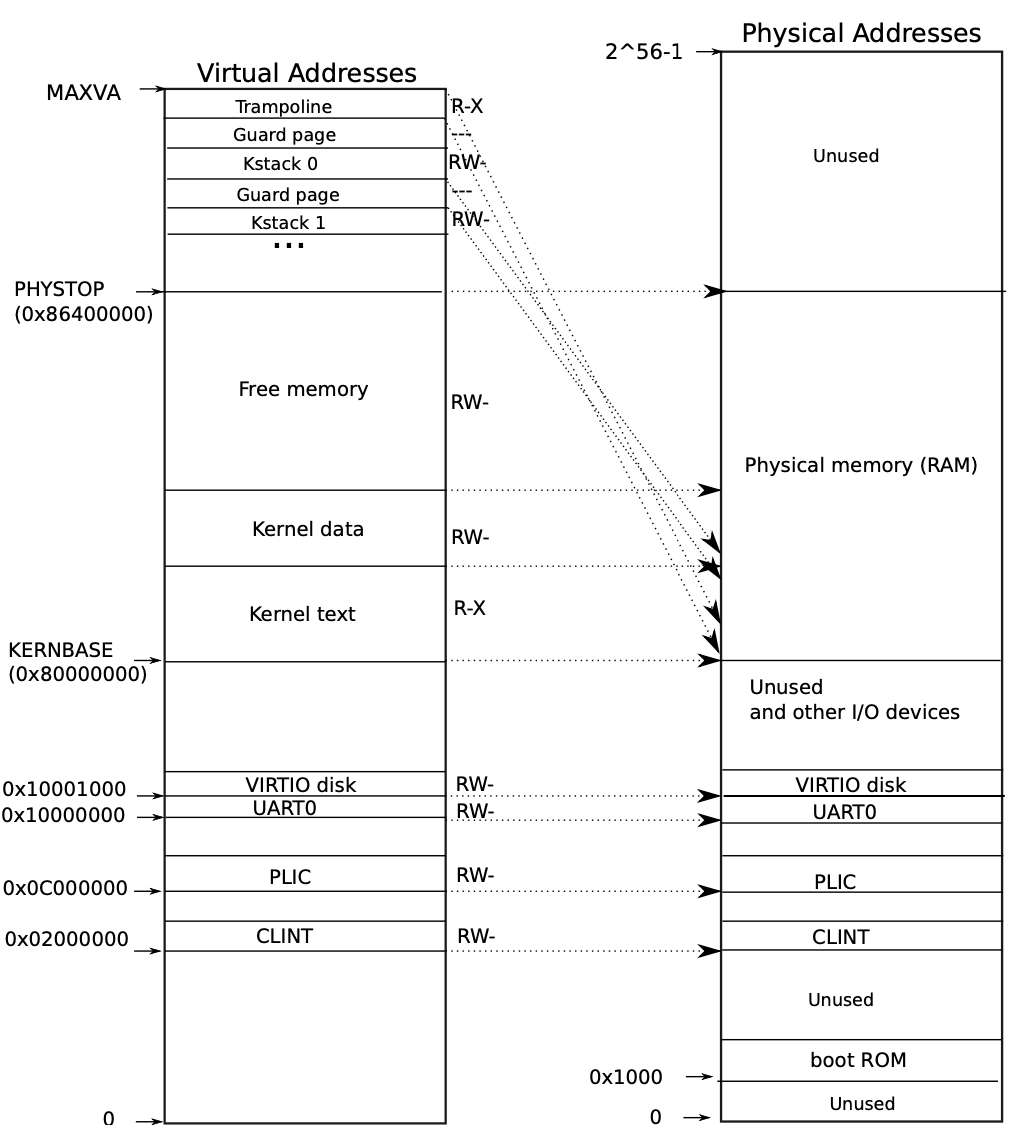
仮想アドレスの高位にはカーネルスタックやトランポリン*6が配置されている。カーネルスタックやトランポリンは1つの物理アドレスに対して2つの仮想アドレスがマッピングされることになる。
カーネルスタックが仮想アドレスの高位に配置されている理由は、スタックのオーバーフローを検知する仕組みを低位 (0x8640_0000以下)に配置した時と比べて簡単に作れるからである。0x8640_0000より高位にカーネルスタックを配置すると、割り当てたスタックの下にガードページという どの物理アドレスにもマップされていないinvalidなページを作成することができ、スタックがオーバーフローして時にガードページにアクセスすると、ガードページはinvalidなのでページフォルト例外が発生しオーバーフローを検知できるというような仕組みになっている。
もしこれと同じ仕組みを低位 (0x8640_0000以下)で実現しようとすると、一度ダイレクトマッピングされている仮想アドレスをアンマップしなければならず、高位に配置するのと比べて処理が複雑になってしまう。
トランポリンが仮想アドレスの高位に配置されている理由は、トランポリンはその性質上ユーザー空間とカーネル空間で同じ仮想アドレスに配置しなければならず、仮想アドレス空間の最高位か最低位に配置するのがOSの実装的に一番シンプルになるが、最低位にはすでに他のものが配置されているなどの理由で配置できないためである。
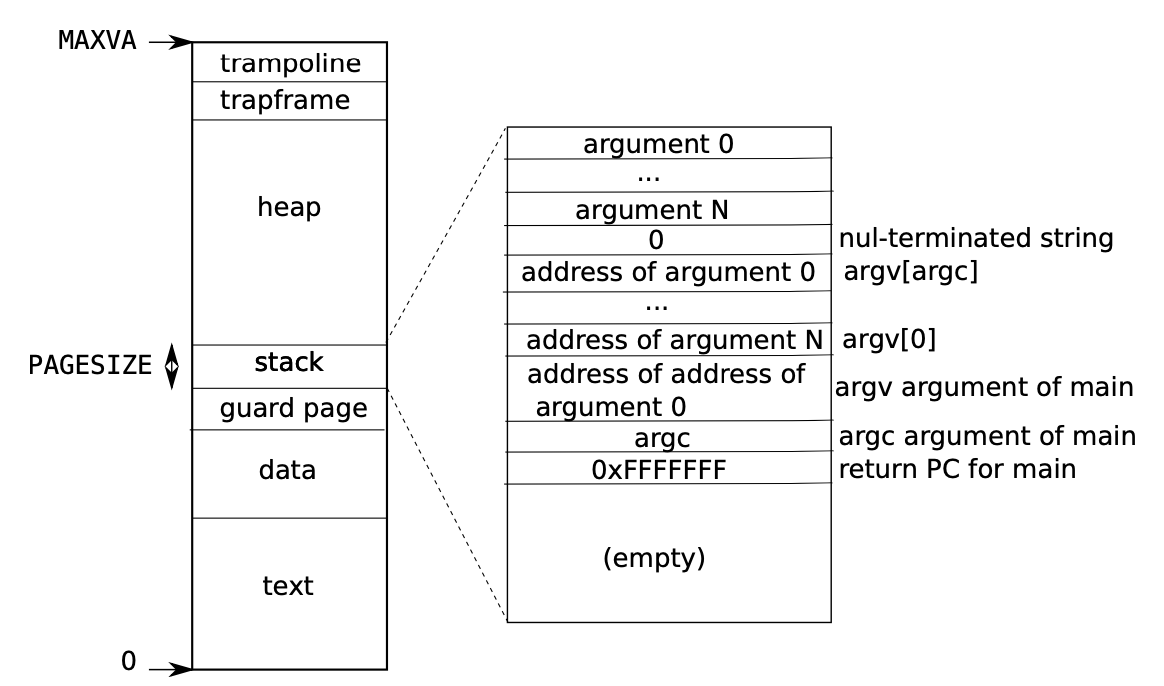
ユーザー空間のメモリレイアウト
ユーザー空間のメモリレイアウトは下図左のようになっている。ユーザースタックは1ページのみ割り当てられ、オーバーフローするとカーネル空間と同じようにガードページにアクセスしページフォルト例外が発生するようになっている。(xv6-riscvのような教育用OSではなく)実際に使われているOSでは、ユーザー空間のスタックがオーバフローした際には新しいメモリを割り当てるようになっているものもあるらしい。
スタックの初期状態は下図右のようになっており、スタックの一番上にはユーザープログラム実行時のコマンドライン引数の文字列が積まれ、その下にそれらへのポインタ (argv)が積まれる。
ユーザー空間のメモリ割り当ての流れ
実際にxv6-riscvでユーザー空間のメモリ 割り当て/解放 がどのように行われているのかを確認するために、sbrk システムコールの処理を追ってみる。sbrkは整数の引数 (n)を1つとり、nが正であればメモリをnバイト確保し、nが負であればメモリをnバイト解放する。
まずはnが正、つまりメモリを新たに割り当てる時の流れを追ってみる。sbrk システムコールが呼び出されると いくつかの処理の後に下の関数 (sys_sbrk()) が呼ばれ、システムコールの引数nを引数としてgrowproc() を呼び出す。
// kernel/sysproc.c uint64 sys_sbrk(void) { int addr; int n; if(argint(0, &n) < 0) // システムコールの引数を取得 return -1; addr = myproc()->sz; if(growproc(n) < 0) return -1; return addr; }
growproc() の中身は下のようになっている。nが正の場合と負の場合で処理が分かれており、nが正の場合は 実行中のプロセスの(ユーザー空間の)ページテーブル と 新たにメモリを確保する前のメモリサイズ と メモリを確保した後のメモリサイズ を引数にとってuvmalloc()(user virtual memory allocate)を呼び出す。growproc() はメモリ確保に成功したら0、失敗したら-1を返す。
// kernel/proc.c int growproc(int n) { uint sz; struct proc *p = myproc(); // 実行中のプロセス(sbrkを呼び出したプロセス)の情報を取得 sz = p->sz; // 実行中のプロセスのメモリサイズ(==すでに割り当てられているメモリの最高位仮想アドレス)を取得 if(n > 0){ if((sz = uvmalloc(p->pagetable, sz, sz + n)) == 0) { return -1; } } else if(n < 0){ sz = uvmdealloc(p->pagetable, sz, sz + n); } p->sz = sz; return 0; }
uvmalloc()は下のような内容になっている。まずoldszをページ境界(4KiB)にアラインメントし、アラインメントしたoldszからnewszまでページサイズずつインクリメントして順々にページを割り当てていく。ページの割り当ては、最初に物理メモリをkalloc()で確保し、その後確保した物理メモリの物理アドレスを mappages()で仮想アドレスにマッピングする流れになっている。mappages()についてはこの記事では詳しく追わないが、引数で指定された仮想アドレスと物理アドレスをマッピングするようなPTEを作成する処理を行っている。
// kernel/vm.c // プロセスのメモリサイズがoldszからnewszになるようにPTEと物理メモリを割り当てる uint64 uvmalloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz) { char *mem; uint64 a; if(newsz < oldsz) return oldsz; oldsz = PGROUNDUP(oldsz); // oldsz(==すでに割り当てられているメモリの最高位仮想アドレス)をページ境界にアラインメント(切り上げ) for(a = oldsz; a < newsz; a += PGSIZE){ mem = kalloc(); if(mem == 0){ // ループの途中で物理メモリの割り当てに失敗したら今までallocした分をdeallocしてreturnする uvmdealloc(pagetable, a, oldsz); return 0; } memset(mem, 0, PGSIZE); if(mappages(pagetable, a, PGSIZE, (uint64)mem, PTE_W|PTE_X|PTE_R|PTE_U) != 0){ // ループの途中でページのマッピングに失敗したら、確保した物理メモリをfreeした後に今までallocした分をdeallocしてreturnする kfree(mem); uvmdealloc(pagetable, a, oldsz); return 0; } } return newsz; }
kalloc()は下のような内容になっており、物理メモリの空き領域からメモリを1ページ分 (4 KiB) 確保して返す。物理メモリの空き領域はrun構造体をノードとする連結リストで管理されている。
// kernel/kalloc.c // メモリ管理の単位(4 KiB)でまとまった空きメモリ領域を表す構造体
// 構造体のアドレスがそのまま物理メモリのアドレスになっている struct run { struct run *next; // 次の空き領域(run) }; struct { struct spinlock lock; struct run *freelist; // 空きメモリを管理する連結リスト } kmem; void * kalloc(void) { struct run *r; acquire(&kmem.lock); // 空きメモリを管理する連結リストの先頭ノードを取り出す r = kmem.freelist; if(r) kmem.freelist = r->next; release(&kmem.lock); if(r) memset((char*)r, 5, PGSIZE); // fill with junk return (void*)r; }
ユーザー空間のメモリ解放の流れ
次にnが負、つまりメモリを解放する時の流れを追ってみる。
growproc()まではnが正の場合と同じだが、nが負の場合はgrowproc()内でuvmdealloc()が呼び出される。
uvmdealloc()は下のような内容になっており、oldszとnewszをそれぞれページ境界にアラインメント(切り上げ)して、解放する必要があるページ数を算出した後uvmunmap()を呼び出す。uvmunmap()についてはこの記事では詳しくは追わないが、まず物理メモリを解放して、次に該当するPTEを削除するような処理を行っている。
// kernel/vm.c uint64 uvmdealloc(pagetable_t pagetable, uint64 oldsz, uint64 newsz) { if(newsz >= oldsz) return oldsz; if(PGROUNDUP(newsz) < PGROUNDUP(oldsz)){ int npages = (PGROUNDUP(oldsz) - PGROUNDUP(newsz)) / PGSIZE; uvmunmap(pagetable, PGROUNDUP(newsz), npages, 1); } return newsz; }
最後に
講義ではメモリ管理の回の宿題として、カーネル内部からページテーブルの切り替えをせずにユーザー(プロセス)空間のメモリを直接参照できるようにするために、プロセスごとにカーネルページテーブルのコピーを保持し、各プロセスのユーザーページテーブルの内容を 保持しているカーネルページテーブル にコピーせよというものが出た。しかしどうやらこの設計は サイドチャネル攻撃脆弱性 や Meltdown/Spectre 脆弱性 があるらしい。せっかくなので次の記事では、ユーザー空間とカーネル空間のページテーブルをまとめて保持することによって生じるこれらの脆弱性についてまとめてみようと思っている。
*1:
https://pdos.csail.mit.edu/6.828/2020/xv6/book-riscv-rev1.pdf
*2:
RISC-V原典 オープンアーキテクチャのススメ | デイビッド・パターソン, アンドリュー・ウォーターマン, 成田 光彰 |本 | 通販 | Amazon
*3:The RISC-V Instruction Set Manual Volume II: Privileged Architecture Document Version 20190608-Priv-MSU-Ratified, p.64 より引用
*4:The RISC-V Instruction Set Manual Volume II: Privileged Architecture Document Version 20190608-Priv-MSU-Ratified, p.72 より引用
*5:MITの講義テキスト, p.31 より引用
*6:ユーザー空間でのトラップベクタやカーネル空間からユーザー空間へreturnするロジックが含まれるコード。トランポリンの実行途中にページテーブルが切り替わっても大丈夫なようにカーネル空間とユーザー空間で同じ仮想アドレスに配置されている。MITの講義テキストのChapter 4で詳しく説明されている。